
 Abstract
Abstract HTML
HTML Reference
Reference Related
Related PDF
PDF












-
Gravitational waves arising from the merger of binary systems were initially detected directly by Advanced LIGO in 2015 [1], setting a seminal milestone in gravitational wave research. These waves encapsulate astronomical information that is not accessible through electromagnetic signals. Thus, their discovery inaugurated the era of gravitational-wave astronomy. To date, Advanced LIGO and Advanced Virgo, the ground-based gravitational wave detectors, have successfully completed their third operational phase, observing nearly 100 GW events associated with the merger of compact binary systems [2−5]. Among these events, there were two mergers involving neutron star-black hole binaries (NSBHs) and two involving binary neutron stars (BNSs). Focusing primarily on binary black hole (BBH) events, the analysis of BBH parameter distributions contributes to our understanding of the massive stellar evolution and binary formation processes [6−8]. Various hypotheses have been postulated to elucidate the formation of compact binaries. One of the most promising theories involves the isolated evolution of binaries in the galactic field, where mechanisms such as common-envelope phases [9−11] and chemically homogeneous evolution [12, 13] play pivotal roles. An alternative theory, contending for prominence, suggests dynamical assembly within densely populated stellar environments such as globular [14, 15], nuclear star [16, 17], and young stellar [18, 19] clusters .
The spin of BH plays a pivotal role not only in analyzing the evolutionary processes of BHs but also in elucidating the hierarchical assembly of multiple generations of stellar-mass BH mergers. BHs resulting from stellar collapse typically exhibit negligible spins, given that the expulsion of matter dissipates angular momentum during the collapse process [20, 21]. Conversely, BHs formed through a multiple generation merger may manifest non-negligible spins. Abbott et al. [22, 23] inferred that BHs demonstrate non-zero spins, with notable misalignments concerning the binary orbital angular momentum. Similar findings were reported in other studies [8, 24, 25]. Galaudage et al. [7] conducted an analysis of BBH merger data from the second LIGO-Virgo gravitational-wave transient catalog (GWTC-2) and identified two distinct subpopulations in which a significant proportion of BHs exhibited negligible spin, contrasting with a smaller fraction demonstrating non-negligible spin. Additionally, Adamcewicz et al. [26] observed in data from GWTC-3 that the both-spin framework, wherein both black holes exhibit apparent spins, outperforms the single-spin framework.
Conclusions derived from diverse methodologies manifest discrepancies. In addition to the aforementioned application of conventional methods for inferring population parameters, there is an emerging trend involving the integration of machine learning techniques for this purpose. Wong et al. [27] exemplify this trend; they trained a machine learning emulator on numerical population synthesis predictions derived from simulations of isolated binary stars. Subsequently, the emulator was incorporated into a Bayesian hierarchical framework to quantify the natal kicks received by BHs at birth. Similarly, Mould et al. [28] utilized fully connected deep neural networks (DNNs) to reconstruct probability density functions. By training these networks with simulations based on various power-law parametrizations combined with hierarchical Bayesian inference, they constrained the properties of BH mergers using data from GWTC-3. Assuming a spin distribution for first-generation BHs characterized by isotropic direction and uniform magnitude, parameterized by the maximum spin
$ \chi_{\rm{max}} $ , Mould et al. [28] determined that the maximum spin was$ \chi_{\rm{max}}=0.39^{+0.08}_{-0.07} $ . The distribution of effective aligned spins was characterized by$ |\chi_{\rm{eff}}|<0.46^{+0.04}_{-0.06} $ , whereas the effective precessing spins displayed multimodal characteristics.Although the traditional Markov chain Monte Carlo (MCMC) method, rooted in Bayesian analysis, has become a popular method used in GW population analysis, MCMC typically incurs high computational costs, particularly in high-dimensional parameter spaces or complex models. Achieving convergence demands a substantial number of samples, leading to large computation times. Additionally, MCMC results are also influenced by the choice of prior distributions. Recently, it has been demonstrated that machine learning methods, especially deep learning (DL), excel in rapidly processing large-scale datasets and high-dimensional problems through parallel computation and efficient optimization algorithms. DL techniques autonomously learn intricate patterns and features from data, thereby diminishing reliance on prior knowledge. They achieve robust performance through training on extensive datasets, offering a compelling alternative to traditional MCMC methods in various applications. In this study, we used a DL methodology to investigate the spin distribution within BBH merger data from the GWTC-3 catalog, as outlined in Ref. [23]. Unlike previous studies [27, 28] where networks were designed to act as a density estimator of a population model, the proposed network was specifically trained to estimate the parameters of a spin model. Consequently, our network architecture is more straightforward and benefits from reduced training times, as it is trained exclusively on spin simulations generated from the Beta model. The model parameters of the spin observation can be extracted by inputting the observational data into the well-trained network.
The rest of the paper is structured as follows. In Section II, we introduce both the data and the spin model. Additionally, we elaborate on the network utilized to express the distribution of observations. Section III presents results, accompanied by a thorough examination of our network through simulations. Discussion and conclusions are presented in Section IV.
-
DL exploits artificial neural networks (ANNs) as an approximate function to characterize the relationship between the input and output data; ANNs typically consist of an input layer to receive input, an output layer to produce results, and one or more hidden layers between them. When there are more than two hidden layers, the neural network is considered a DNN. DL has been widely applied in the fields of cosmology [29−32] and gravitational wave astronomy research [33−40]. In this study, we constructed a fully connected DNN to investigate the spin magnitude distribution of BBHs through GWTC-3 [23]. Excluding events involving neutron stars, we extracted a total of 70 BBH merger events for the study of population information. For visualization purposes, the spin magnitudes of the available BBH events are depicted in Fig. 1.

Figure 1. (color online) Spin magnitudes of BBH events utilized in this study extracted from [23];
$ \chi_1 $ and$ \chi_2 $ denote the spin magnitudes of the first and second black holes, respectively.Our methodology is grounded in the spin magnitude model, wherein each component spin magnitude of BBH mergers is described by a Beta distribution [23, 41]:
$ p(\chi \mid \alpha, \beta) \propto \chi^{1-\alpha}(1-\chi)^{1-\beta},$

(1) Here, χ signifies the magnitude spin of one of the BHs in the BBH merger and is constrained within the interval
$ \chi\in[0,1] $ . The parameters α and β function as normalization constants, adhering to the constraints$ \alpha\geq1 $ and$ \beta\geq1 $ to ensure a non-singular distribution. We utilized simulated data generated from the aforementioned model to facilitate network training. Although the direct utilization of the 70 spin magnitude observations could suffice for obtaining distribution parameters, maximizing the training efficiency through data preprocessing is essential. Consequently, we segmented the 70 spin magnitudes into 10 bins and employed the normalized counts of each bin as training features. In essence, the probability density values served as features, while the corresponding parameters acted as labels.During the preparation of training data, for the purpose of precision enhancement, we directly generated training data, i.e., probability density samples, from the distribution model (i.e., Eq. (1)), based on a series of parameters denoted by
$ \boldsymbol{y}_i=\{\alpha,\beta\}_i $ (the training labels), where$ \alpha\in[1.2,8] $ and$ \beta\in[1.2,8] $ , both with an interval of 0.2, resulting in a total of 35$ \times $ 35 parameter combinations. For the i-th set of parameters, the corresponding ten probability density values (the training features) are represented by a vector$ \boldsymbol{x}_i $ .The structure of the proposed DNN, comprising three hidden layers, is depicted in Fig. 2. The initial layer, i.e., the input layer, composed of ten neurons, accepts the probability density vector, while the final layer, i.e., the output layer, containing two neurons, outputs the parameter vector. Intermediary between these layers are three hidden layers, the first with 200 neurons, the second with 400 neurons, and the third with 200 neurons. These layers facilitate the transformation of information from preceding to succeeding layers through a combination of linear transformations and nonlinear activations, the latter being instrumental in enhancing the network performance.
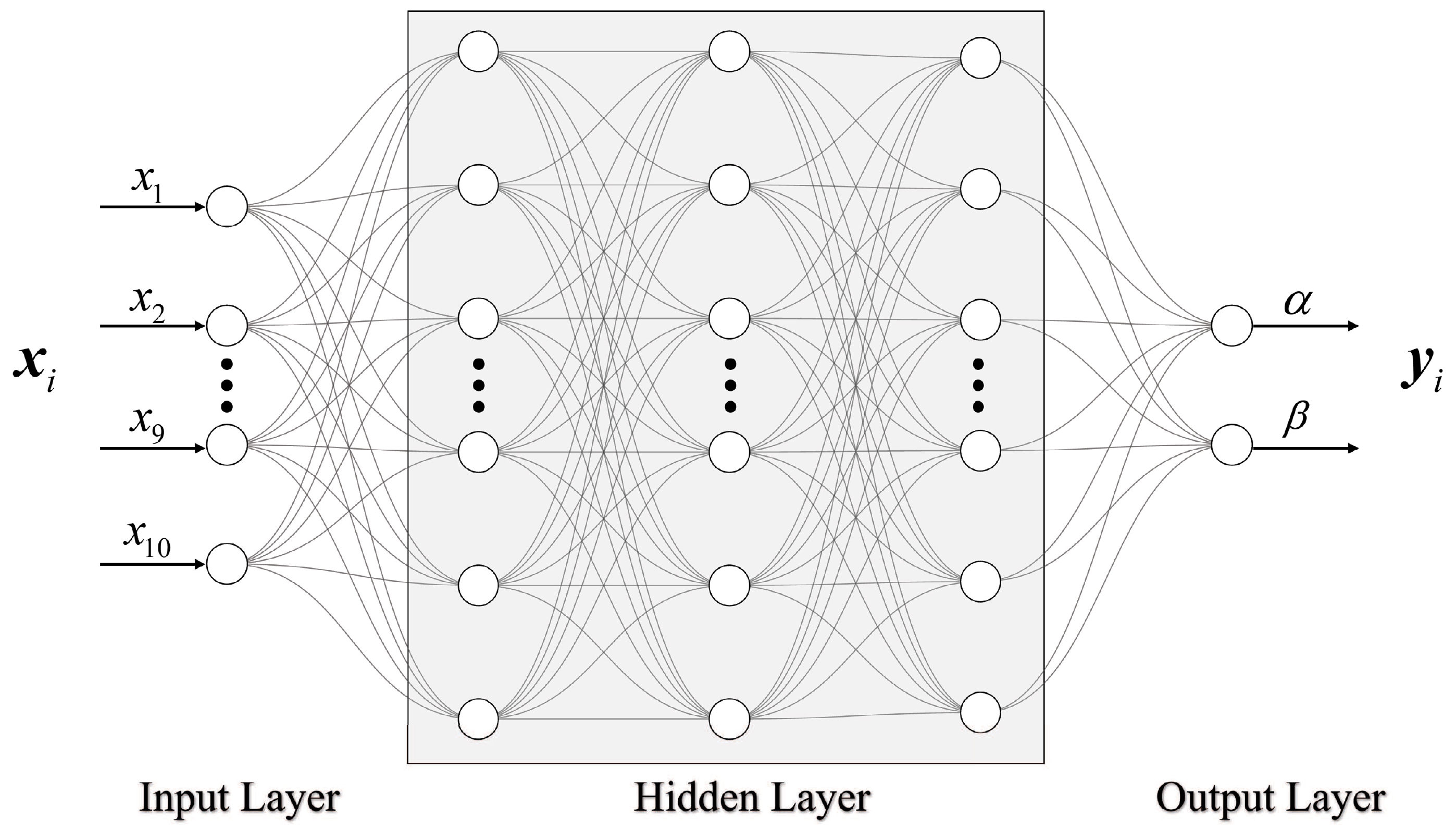
Figure 2. Architecture of the proposed DNN, which features three hidden layers. The input and output are the probability density values and the corresponding distribution parameters, respectively. The number of circles represents the number of neurons in each layer.
The matrix algorithms employed within the proposed DNN are expressed as follows:
1) Initialization (for l=1):
$ \boldsymbol{A}^l=\boldsymbol{X}, $

(2) 2) Hidden layers (for l=2 to 4):
$ \boldsymbol{A}^l=\sigma\left(\boldsymbol{A}^{l-1} \boldsymbol{W}^l+\boldsymbol{B}^l\right), $

(3) 3) Output (for l=5):
$ \hat{\boldsymbol{Y}}=\boldsymbol{A}^{l-1} \boldsymbol{W}^l+\boldsymbol{B}^l, $

(4) here, the input matrix
$ \boldsymbol{X} $ possesses dimensions$ m\times n $ , where m represents the size of the training set and n signifies the number of features;$ \boldsymbol{A}^{l} $ denotes the output of the l-th layer, characterized by dimensions$ m\times k $ , where k corresponds to the number of neurons in the l-th layer;$ \boldsymbol{W}^{l} $ denotes the weight matrix connecting the$ (l-1) $ -th layer to the l-th layer, with dimensions$ j\times k $ , where j denotes the number of neurons in the$ (l-1) $ -th layer;$ \boldsymbol{B}^{l} $ represents the bias matrix, with dimensions$ m\times 1 $ ; σ denotes the activation function, which corresponds to the rectified linear unit (ReLU) function:$ \sigma(x)=\left\{\begin{array}{ll} 0, & x \leq 0 \\ x, & x>0 \end{array}\right.$

(5) ${\hat{\boldsymbol Y}} $ represents the prediction of the DNN, with dimensions$ m\times p $ , where p denotes the number of labels. Note that computations within the input and output layers are linear. We employed the mean squared error (MSE) function as the loss function to quantify the difference between the prediction${\hat{\boldsymbol Y}} $ and the labels$ \boldsymbol{Y} $ , leveraging the Adam optimizer to minimize this loss. The learning rate and training epoch were set to 0.001 and 5000, respectively. The ratio of the training set to the validation set was maintained at 8:2. Throughout the training of the DNN with data, the hyperparameters$ \boldsymbol{W} $ and$ \boldsymbol{B} $ in each layer were determined, culminating in a well-trained DNN capable of approximating a function$ \boldsymbol{Y}=f_{\boldsymbol{W},\boldsymbol{B}}\left(\boldsymbol{X}\right) $ . Consequently, the parameters of the spin magnitude distribution$ \{\alpha,\beta\} $ can be predicted by inputting the spin observation distribution.The DNN was trained using the TensorFlow package
1 . The MSE losses throughout the training epochs for both the training and validation sets are shown in Fig. 3. Note that the MSE loss for the training set approaches 10−2 around epoch 2000, while the MSE loss for the validation set also reaches its minimum near this epoch. This convergence suggests that the performance of the proposed model meets the practical requirements. To further assess the predictive accuracy of the well-trained DNN, a novel test set was generated for prediction evaluation. The examination reveals that the variance between the real values and predictions does not exceed 0.02.
Figure 3. (color online) MSE loss as a function of the number of training epochs for both the train (blue) and validation (orange) sets.
-
Utilizing the well-trained DNN, we can infer the distribution parameters of a dataset with an unrestricted number of BBH events, benefiting from segmenting the data into 10 bins. Notably, within the spin sample of the largest BH in GWTC-3, denoted as
$ \chi_1 $ , the parameters manifest as$ \alpha=4.13 $ and$ \beta=5.62 $ . Similarly, within the spin sample of the smaller BH in GW events, denoted as$ \chi_2 $ , the parameters were determined to be$ \alpha=13.08 $ and$ \beta=15.33 $ . For comparative analysis, we employed the MCMC approach to estimate the distribution parameters. Assuming uniform priors for both α and β within the interval [1, 30], the parameters were constrained as$ \alpha = 3.63^{+0.55}_{-0.51} $ and$ \beta = 5.40^{+0.80}_{-0.73} $ for$ \chi_1 $ , and$ \alpha = 18.08^{+1.99}_{-1.82} $ and$ \beta = 21.13^{+2.44}_{-2.20} $ for$ \chi_2 $ . The results for$ \chi_1 $ align with those obtained from the DNN within the 1σ confidence level, whereas the results for$ \chi_2 $ exhibit a deviation from the DNN outcomes. The corresponding probability density functions (PDFs) are illustrated in Fig. 4, where the MCMC method assigns greater significance to bins with a higher number of spins compared to the DNN, which considers the distribution in its entirety. Regarding computational efficiency, the MCMC method exhibited significantly higher time consumption compared to the DL method. Notably, the uncertainties of parameters cannot be provided with one sample using the DL method. Furthermore, it is not suitable either to determine the parameters only with the central values of a spin sample.
Figure 4. (color online) Histograms of spin observations: left:
$ \chi_1 $ , right:$ \chi_2 $ . The red and olive green lines represent the predictions of DNN and MCMC methods, respectively.To address these limitations, a Monte Carlo-bootstrap (MC-bootstrap) method [42] is proposed. The procedural steps are as follows: 1) sampling the spin magnitude from the posterior distributions for the larger and smaller BHs within a specific GW event to generate samples similar to observations, denoted as sample of
$ \chi_1 $ and sample of$ \chi_2 $ , respectively; 2) segregating each sample into 10 bins and normalizing the count within each bin; 3) utilizing the normalized counts of each sample as input to the well-trained DNN to deduce the corresponding parameters$ \{\alpha,\beta\} $ ; 4) iterating through the aforementioned steps 1000 times to obtain parameter chains.The 2-dimensional confidence contours and 1-dimensional PDFs for the two samples are depicted in Fig. 5. Within the sample of
$ \chi_1 $ , the parameters were predicted to be$ \alpha=1.38^{+0.34}_{-0.21} $ and$ \beta=1.64^{+0.38}_{-0.26} $ . Within the sample of$ \chi_2 $ , the parameters were predicted to be$ \alpha=1.37^{+0.31}_{-0.20} $ and$ \beta=1.63^{+0.30}_{-0.20} $ . The parameters were also estimated via the MCMC method utilizing MC samples. This approach yields parameter estimates of$ \alpha=1.27^{+0.44}_{-0.28} $ and$ \beta=1.62^{+0.71}_{-0.45} $ for$ \chi_1 $ , and$ \alpha=1.38^{+0.51}_{-0.33} $ and$ \beta=1.61^{+0.64}_{-0.43} $ for$ \chi_2 $ . We present the corresponding 2-dimensional confidence contours and 1-dimensional PDFs in Fig. 5 for comparison. These results from the MCMC method demonstrate consistency with those from the DNN within the 1σ confidence level. By contrast, note that the results obtained with MC samples diverge from the predictions based on central spin data within the$ 1\sigma $ confidence interval, which is attributed to the significant uncertainties inherent to spin observations. Our results demonstrate that it is not sufficient to fit the population model only with the central values of the spin observations. The distributions of the component spin magnitudes of BBHs within the parameters inferred from the DNN are shown in Fig. 6. Notably, the distributions of spin magnitudes exhibit peaks at$ \chi_1=0.30^{+0.05}_{-0.07} $ and$ \chi_2=0.38^{+0.05}_{-0.02} $ , seemingly suggesting the presence of non-zero spin for both black holes involved in the BBH merger.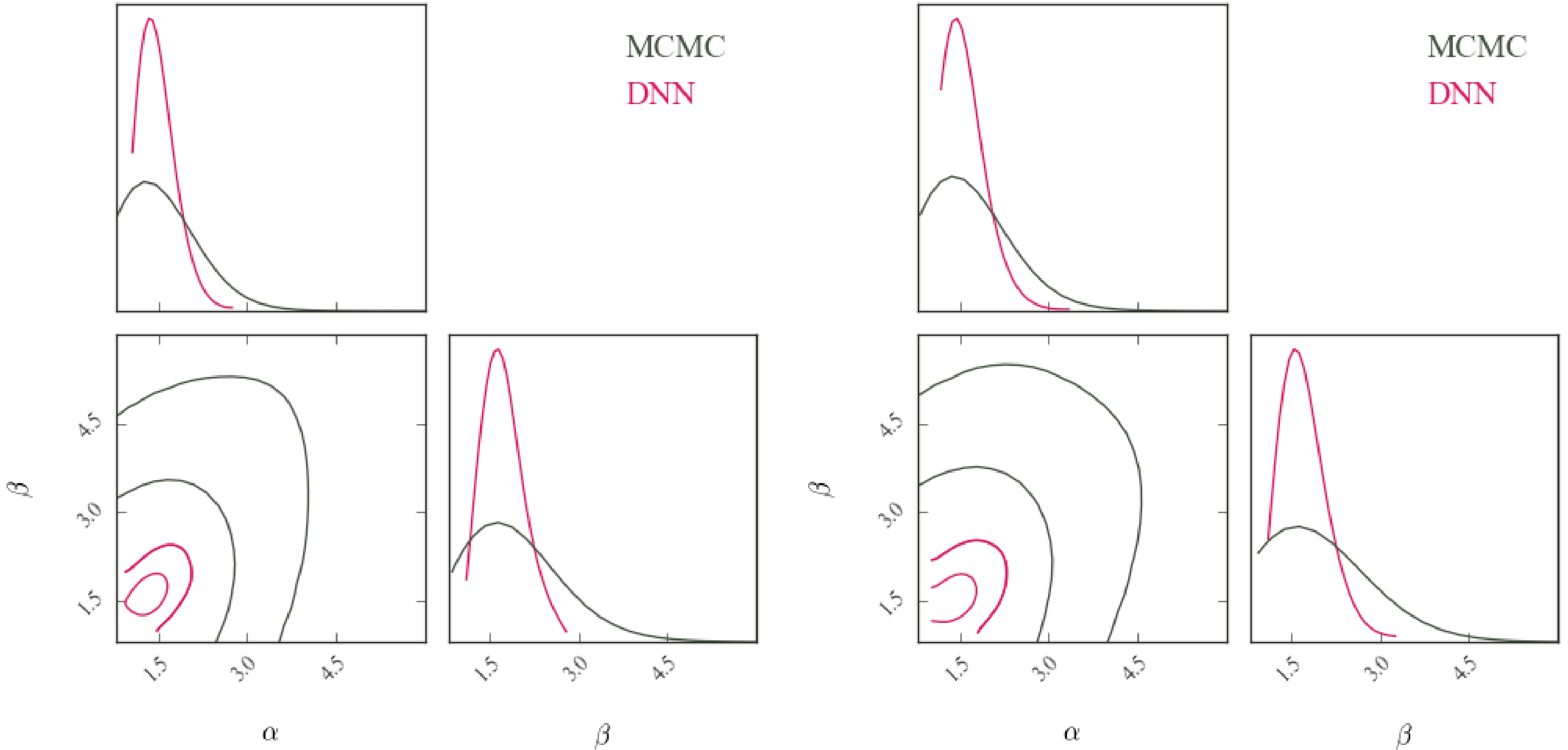
Figure 5. (color online) 2-dimensional confidence contours and 1-dimensional PDFs for two samples: left:
$ \chi_1 $ , right:$ \chi_2 $ .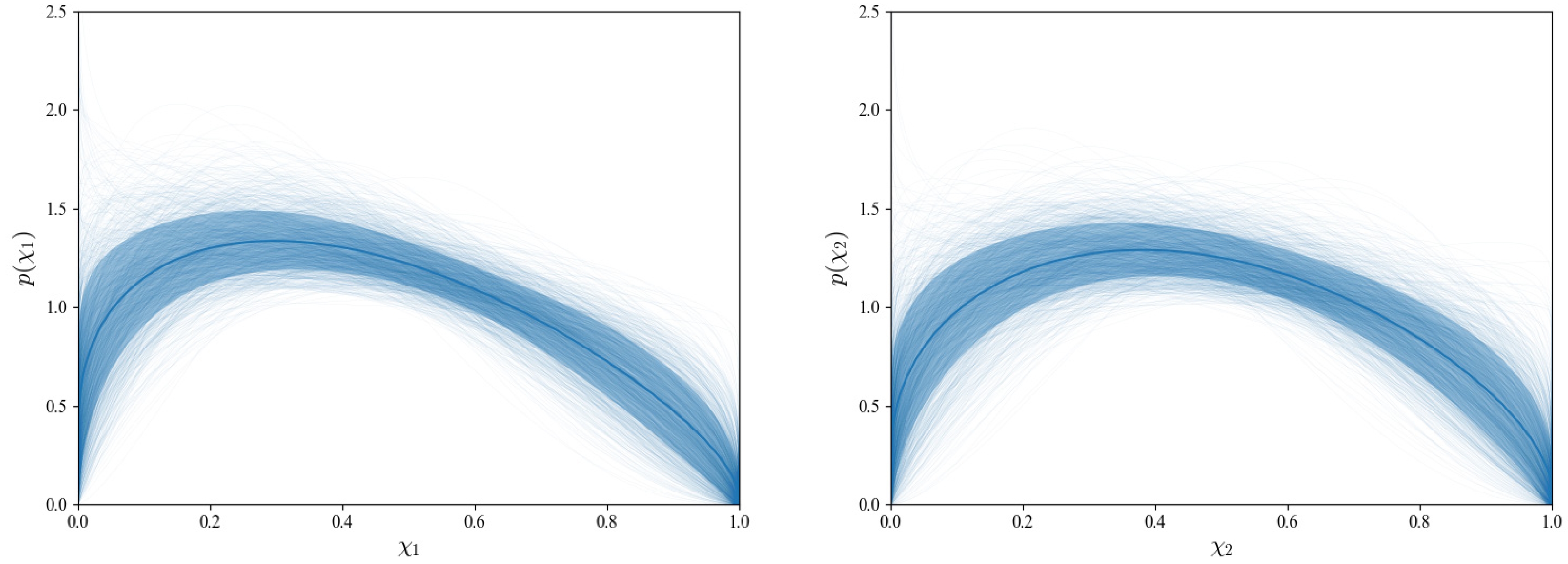
Figure 6. (color online) Distribution of component spin magnitudes: left:
$ \chi_1 $ , right:$ \chi_2 $ . The solid blue lines and shaded regions denote the medians and central 1σ credible bounds, respectively.To investigate the relationship between observed uncertainty and population parameter predictions, we reduced the uncertainty of observations to simulate data and constrain the parameters. In the context of simulation, our focus was directed solely on one spin sample, i.e., the spin sample of the larger BH. Mock samples were generated via MC-bootstrap, sampling from a Gaussian distribution
$ G(\chi,\Delta_{\chi}/C) $ , where χ denotes the observed central value of the spin sample of the larger BH,$ \Delta_{\chi} $ represents the observation error, and C signifies the coefficient by which the error is reduced. Subsequently, mock samples I and II were generated setting$ C=5 $ and$ C=10 $ , respectively, and the corresponding parameters were predicted using the proposed DNN. The results are presented in Fig. 7, where the parameters predicted using observed central spins are denoted by red points in the 2-dimensional confidence contours. Notably, the prediction of mock sample I ($ C=5 $ ) exhibits a slight deviation from the results of the central spin data prediction within the$ 1\sigma $ confidence level, while the prediction of mock sample II ($ C=10 $ ) aligns with it. These comparisons indicate that high-precision spin measurements can be directly used to rapidly obtain group parameter information in the future.
Figure 7. (color online) 2-dimensional confidence contours and 1-dimensional PDFs for mock samples whose uncertainties were reduced by 5 (left) and 10 (right). The red points represent the parameters predicted using the observed central spins.
Given the anticipated surge in GW detections, projected to reach 104–105 events annually owing to the heightened sensitivity of third-generation GW detectors such as the Einstein Telescope [43], we comprehensively investigated the efficacy of the proposed DNN over varying data volumes, encompassing both present and projected future scenarios. Leveraging a fiducial spin distribution characterized by parameters
$ \alpha=3.2 $ and$ \beta=4.5 $ , we generated two distinct samples comprising 70 and 1000 data points, representative of current and anticipated future data volumes, respectively. By partitioning each sample into 10 bins and inputting counts into our well-trained DNN, we derived predicted parameters. This procedure was iterated 1000 times to obtain the corresponding parameter chains. Additionally, we explored the influence of varying bin numbers, i.e., 5, 10, and 20, on parameter estimation. The results are presented in Table 1 and Fig. 8, wherein the fiducial parameters are denoted by red points in the 2-dimensional confidence contours of parameters.70 1000 α β α β 5 $ 3.13^{+0.58}_{-0.48} $ 

$ 4.34^{+0.77}_{-0.68} $ 

$ 2.92^{+0.14}_{-0.12} $ 

$ 4.09^{+0.21}_{-0.19} $ 

10 $ 3.45^{+0.67}_{-0.54} $ 

$ 4.78^{+0.95}_{-0.73} $ 

$ 3.12^{+0.18}_{-0.15} $ 

$ 4.41^{+0.24}_{-0.20} $ 

20 $ 3.68^{+0.76}_{-0.58} $ 

$ 5.02^{+1.01}_{-0.77} $ 

$ 3.21^{+0.17}_{-0.15} $ 

$ 4.49^{+0.25}_{-0.20} $ 

Table 1. Parameters of samples with 70 and 1000 data points.
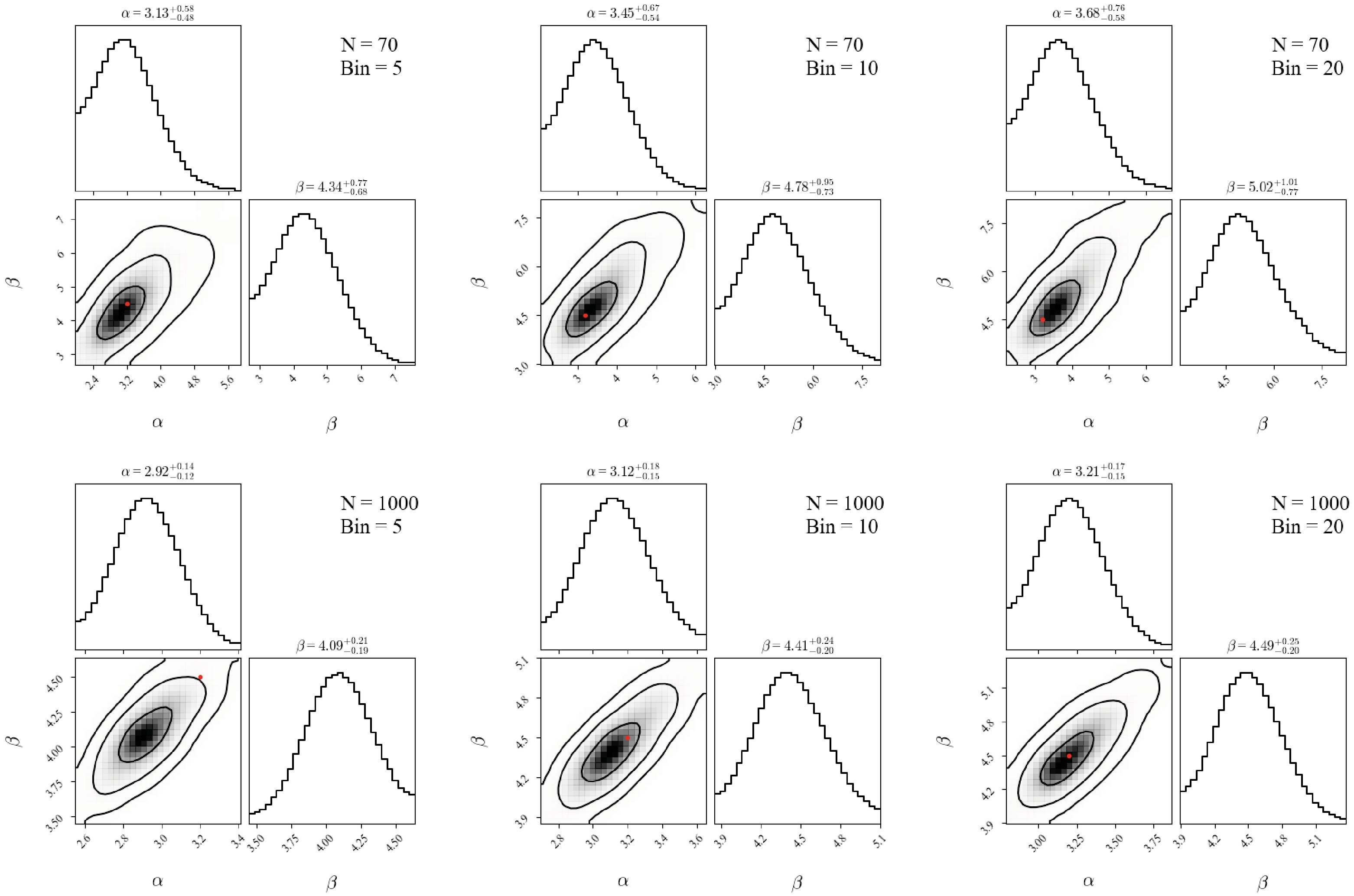
Figure 8. (color online) 2-dimensional confidence contours and PDFs of parameters of samples with 70 and 1000 data points.
It can be observed that, within the context of 70 data points, the predicted parameters consistently align with the fiducial values within the 1σ confidence level across all bin numbers. For the dataset comprising 1000 data points, a deviation from the fiducial values of approximately 2σ confidence level was observed when utilizing 5 bins. However, congruence with the fiducial values within the 1σ confidence level was achieved for both 10 and 20 bins. Our results underscore the importance of employing an adequate number of bins to effectively capture the distribution characteristics, particularly for larger datasets. We conclude from the present study that the use of 10 bins within the DNN framework is deemed suitable for both current and anticipated future data volumes, facilitating robust characterization of spin distributions across varying sample sizes.
-
Spin encapsulates pivotal information regarding the formation and evolution of black holes. Numerous studies have delved into the spin dynamics of BBH systems using GW observations. However, the debate over the spin characteristics of BHs involved in BBH mergers remains contentious. In this study, we employed a DL approach to probe the spin distribution of BBH systems within the GWTC-3 catalog. We devised a fully connected DNN tailored to extract population parameters pertaining to spin, leveraging the framework of the Beta distribution. While DL methods have been previously proposed for investigating the GW population [28], our approach diverges from their work. Mould et al. [28] merged DL methodologies with hierarchical Bayesian inference to explore the GW population landscape. In their study, DL techniques were utilized to reconstruct population models encompassing mass, spin, selection functions, and branching functions across merger generations. In contrast, our methodology is singularly focused on the spin model, inferring population parameters solely based on observational data. Avoiding hierarchical Bayesian techniques, our parameter constraint process is expedited. Furthermore, our approach based on segregating data into 10 bins is flexible for the future accommodation of GW event datasets of varying sizes. To determine the parameters and associated uncertainties, we employed Monte Carlo-bootstrap sampling to generate samples for parameter prediction using the proposed DNN, subsequently assessing uncertainty through 1000 iterations of sampling. Within the spin sample of the larger BH, the parameters characterizing the spin distribution were constrained to
$ \alpha=1.30^{+0.25}_{-0.18} $ and$ \beta=1.70^{+0.42}_{-0.29} $ . Within the spin sample of the smaller BH, the parameters were found to be$ \alpha=1.37^{+0.31}_{-0.20} $ and$ \beta=1.63^{+0.30}_{-0.20} $ . Notably, these parameters deviate from the results based on the central values of the spin data confidence level. This deviation is attributed to the substantial uncertainty associated with spin observations, which hinders the generation of samples closely resembling the central values. Upon reducing the spin uncertainty by a factor of 10, the parameters aligned with the central value predictions within the 1σ confidence level. Additionally, we also compared the parameters of the spin model resulting from DL and MCMC method; we found that they are consistent with each other within the 1σ confidence level.The spin distribution has been extensively investigated using various methodologies, primarily based on hierarchical Bayesian inference techniques, resulting in different conclusions [7, 22−24, 44, 45]. For instance, Abbott et al. [44] considered the degeneracy between mass and spin, modeling these distributions together using a Beta distribution. Their analysis of 10 BBH mergers revealed that the spin distribution peaks at approximately 0.2, with 90% of BH spins less than 0.55 and 50% less than 0.27. Similar results were observed in the Beta model using the GWTC-2 data [7]. Golomb and Talbot [45], without making strong assumptions about the spin shape, used flexible cubic spline interpolants to model the spin observations of 59 events in the third observing run (O3) of the LIGO-Virgo network, finding that 77.1% of BHs have spin magnitudes less than 0.5, with 50% below 0.25. The proportion of high spin magnitudes appears to increase with the number of detected GW events. However, in the GWTC-3 analysis, Abbott et al. [23] reported a peak at 0.13 with a tail extending toward larger values, with 50% of BHs having spin magnitudes below 0.25. In this study, we modeled the spin observations of GWTC-3 with a Beta distribution and found that the distributions of spin magnitudes exhibit peaks at
$ \chi_1=0.30^{+0.05}_{-0.07} $ and$ \chi_2=0.38^{+0.05}_{-0.02} $ . Specifically, we observed that in the$ \chi_1 $ distribution, 61% of BHs have spin magnitudes less than 0.5, with 50% below 0.41. In the$ \chi_2 $ distribution, 56% have spin magnitudes less than 0.5, with 50% below 0.45, suggesting a higher spin magnitude compared to previous studies. These differences highlight the impact of varied methodologies, data samples, and spin models on the inferred spin distributions. Unlike previous studies, our methodology does not incorporate a broad range of factors, such as merger rates and selection effects. Additionally, our data analysis focused exclusively on spin, without accounting for variables such as mass and spin tilt angle.In conclusion, our findings support the notion that the spin distribution adheres to a Beta model, exhibiting a peak around ~0.35, suggesting the likelihood of both BHs in the BBH merger possessing non-zero spins. BHs with non-zero spins may stem from multi-generational mergers within hierarchical BH merger scenarios [24, 46]. As two BHs merge, the spin of the resulting BH reflects a combination of the spins of the merging BHs and the orbital angular momentum at plunge. In hierarchical mergers, prevalent in star clusters and active galactic nuclei (AGNs), the spin of BHs resulting from mergers involving second or higher-generation BHs may be significant compared to first-generation BHs originating from stellar collapse. Moreover, if the spins of the binary BHs are aligned with the orbital angular momentum, the resultant remnant spin is likely to be larger.
Interestingly, this study represents an exploratory endeavor aimed at examining spin distribution through the utilization of DL methodologies, specifically relying on existing GW observations from ground-based detectors. Consequently, certain factors, such as selection effects, were not taken into account in our analysis. The primary objective of our investigation was to provide a methodological framework conducive to analyzing forthcoming, substantially larger GW datasets, thereby facilitating a comprehensive understanding of BH characteristics within our cosmic milieu. This aspiration is anticipated to be accomplished with the advent of both ground-based and space-based gravitational wave detectors. In this study, we did not compare distinct spin models utilizing the proposed DNN. Nevertheless, the DNN architecture holds potential as a modular template, serving as a foundation for constructing more intricate DNNs capable of comparing and inferring various spin models in future research endeavors.
Inferring the spin distribution of binary black holes using deep learning
- Received Date: 2024-05-16
- Available Online: 2024-10-15
Abstract: The spin characteristics of black holes offer valuable insights into the evolutionary pathways of their progenitor stars. This is crucial for understanding the broader population properties of black holes. Traditional hierarchical Bayesian inference techniques employed to discern these properties often demand substantial time, and consensus regarding the spin distribution of binary black hole (BBH) systems remains elusive. In this study, leveraging observations from GWTC-3, we adopted a machine learning approach to infer the spin distribution of black holes within BBH systems. Specifically, we developed a deep neural network (DNN) and trained it using data generated from a Beta distribution. Our training strategy, involving the segregation of data into 10 bins, not only expedites model training but also enhances the versatility and adaptability of the DNN to accommodate the growing volume of gravitational wave observations. Utilizing Monte Carlo-bootstrap (MC-bootstrap) to generate observation-simulated samples, we derived spin distribution parameters:



 DownLoad:
DownLoad: